A GAN-BERT Based Approach for Bengali Text Classification with a Few Labeled Examples
Dec 13, 2022· ,,,,
,,,,
Raihan Tanvir
MD Tanvir Rouf Shawon
Md Humaion Kabir Mehedi
Md Motahar Mahtab
Annajiat Alim Rasel
Abstract
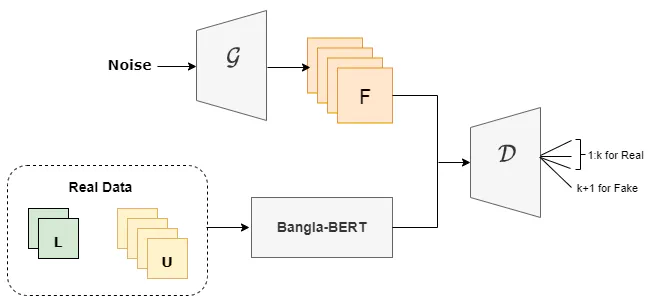
Basic machine learning algorithms or transfer learning models work well for language categorization, but these models require a vast volume of annotated data. We need a better model to tackle the problem because labeled data is scarce. This problem may have a solution in GAN-BERT. To classify Bengali text, we developed a GAN-BERT based model, which is an adapted version of BERT. We used two different datasets for this purpose. One is a hate speech dataset, while the other is a fake news dataset. To understand how the GAN-Bert and basic BERT models behave with Bangla datasets, we experimented with both. With a small quantity of data, we were able to get a satisfactory result using GAN-BERT. We also demonstrated how the accuracy increases as the number of training samples increases. A comparison of performance between traditional BERT based Bangla-BERT and our GAN-Bangla-BERT model is also shown here, where we can see how these models react to a small number of labeled data.
Type
Publication
2022 19th International Conference on Distributed Computing and Artificial Intelligence